パイソンエンジニア部
パイソンエンジニア部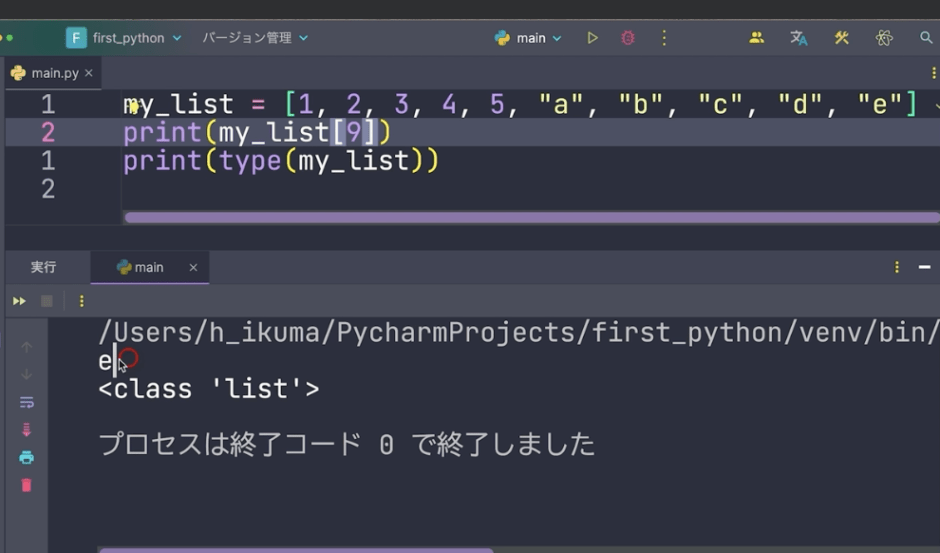

前回の続きです。
複数のデータを格納できるリストを学び、任意の値を取り出せるようになる
続いてリスト型に複数のデータを格納する方法を見ていきましょう。
型も残すところあと3つ。頑張っていきましょう。
まずリストというのは一体何かというと、複数のデータを格納するための型です。よく使われます。
格納するデータ型は何でも大丈夫です。そして型は並び順情報を持っています。
入れ子のことをネストなんて言いますが、そのネストもできます。つまりリストの中にリストを入れられます。
リストの定義方法
リストを定義するにはこのように書きます。

角括弧でデータを中に書いていきます。データはカンマで区切ります。このデータはカッコ内にいくらでも入れることができます。
このサンプルコードでは、1カンマ、2カンマ、3カンマというふうに、1から9までのデータの塊を my_list という変数に入れています。
そして、この作ったリストをプログラムからどのように操作するかというと、取り出すときにインデックスというものを使って取り出します。
インデックスというのは左から数えて何番目という数字です。
といってもよくわからないと思いますので、ここまでをPyCharmでやってみましょう。
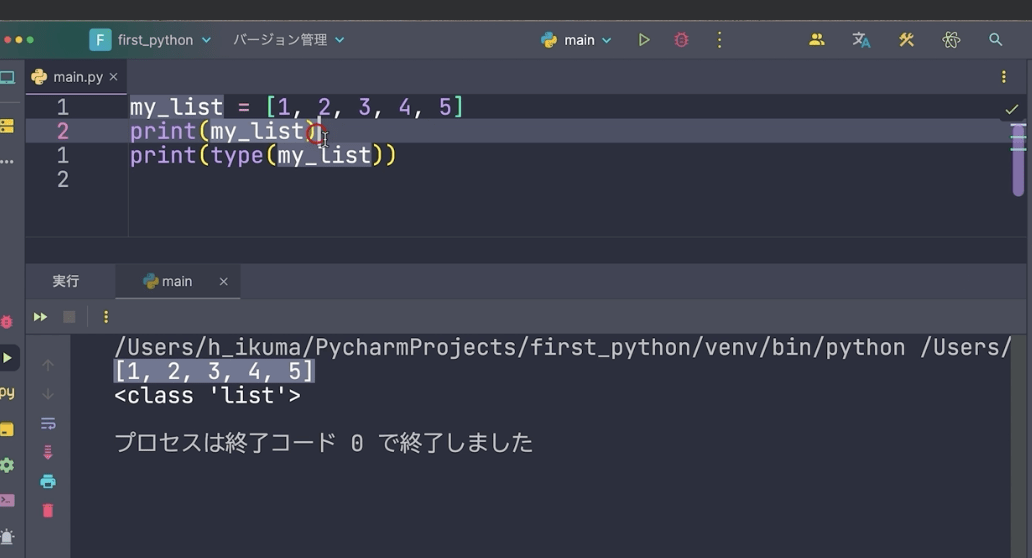
まずはリストの定義からです。my_list = [ ]の中にカンマで区切って1〜5までのデータを格納します。
するとこの my_list の中には1から5までの数字が入ったリストが格納されます。
print(my_list)で全リスト表示してみます。次にprint(type(my_list))と入力します。
このように1から5までのデータがこの中には格納されていることが表示されます。
そして <class ‘list’> の部分は型がリスト型ということを表しています。
格納するデータ型は自由で、数字に続いてカンマでアルファベットのような別のデータ型を混ぜることもできます。

上の画像のように、アルファベットを混ぜて表示してもリスト型であることは変わりません。
そしてこのリスト型は並び順情報を持っています。リストを定義した時と同じ順番でターミナルに表示されています。
並び順をデータとして持っていると言うと当たり前のように聞こえるかもしれませんが、Pythonでは set という並び順情報を持たない型もあります。
set は本シリーズでは扱いませんが、並び順情報を持っているもの、持っていないものがあります。
そしてリストは並び順情報を持っています。そして、リストから値を取り出す時はインデックスを使って取り出します。これは左から数えて何番目という数字です。そして、このインデックスは0から始まります。プログラミングの世界は0と1の世界です。2進数ですね。2進数の0と1でプログラムの世界は作られるわけです。インデックスはそのため、0から始まるということになります。
0から始まるというのはプログラミングに馴染みがない方にはわかりにくいかもしれませんが、プログラミングでは0から始まることが基本です。
インデックスでリストから値を取り出す
それではこのリストから値を取り出してみましょう。

ではインデックスを使って取り出します。
このリストの1を取り出してみます。この1を取り出すには
print(my_list[0]) と入力します。これでプログラムを実行すると結果が、1と表示されます。
この1は、リストの0番目の値ということです。では5という値を取り出すにはどうすればいいでしょうか。ちょっと考えてみましょう。
この5を取り出すためには、リストの左から数えます。 インデックス4が5です。
print(my_list[4])
と入力すると5を取り出すことができます。
もし、このリストから、eを取り出すためにはどうすればいいでしょうか?
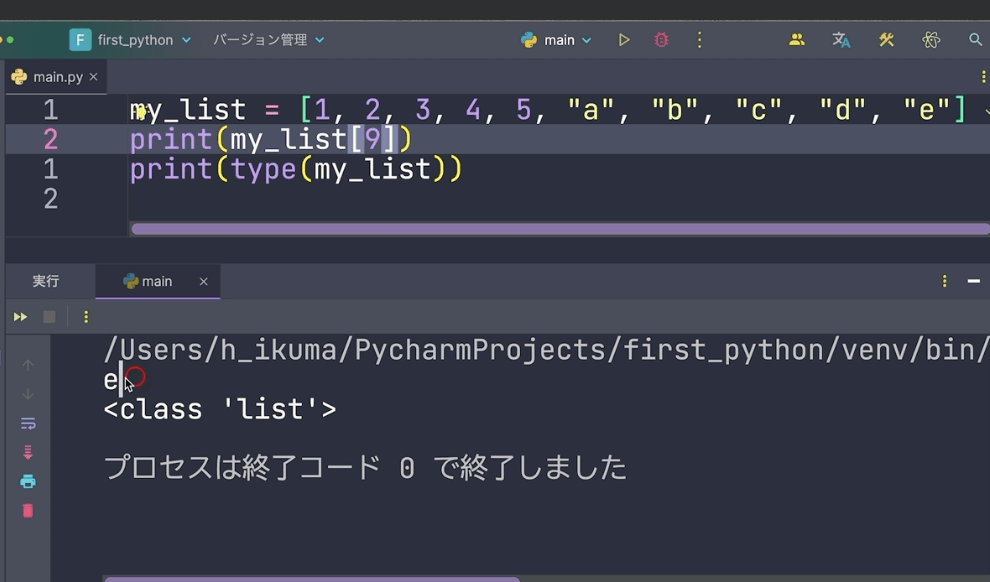
このeを取り出すためにはどうするかというと、インデックス9を指定します。
print(my_list[9])
ちなみに上記のようにリストの最後の値を取り出す時は、先頭から数えて行っても可能ですが、もっといい方法があります。
print(my_list[-1])
-1とすると、リストの一番最後のことを表します。この方法でもeを取り出せます。
最後のデータが-1ですから、その一つ前の-2とすると、dがとりだせます。
ではこのcをうしろから取り出してみます。この場合、後ろから3番目ですから、-3とします。
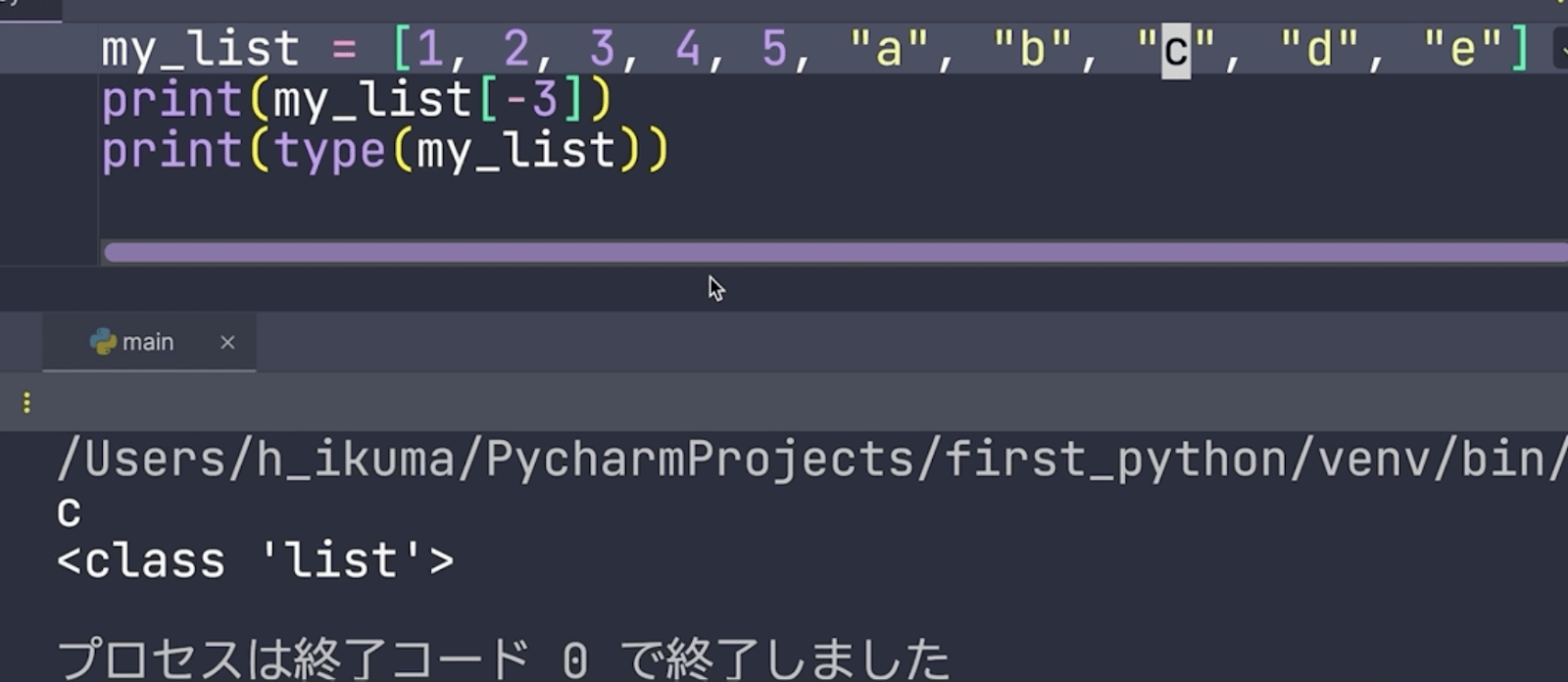
これがインデックスを使った取り出し方です。インデックスを使う場合は一つだけ取り出すことができます。そしてインデックスは0から始まります。
マイナスで表記すると、後ろから数えて何番目という指定になります。
スライスで値を取り出す
次はスライスという方法もありますので、こちらも見ていきます。
スライスというのは任意の範囲を取り出すというものです。:(コロン)で区切ります。
print(my_list[0:5])
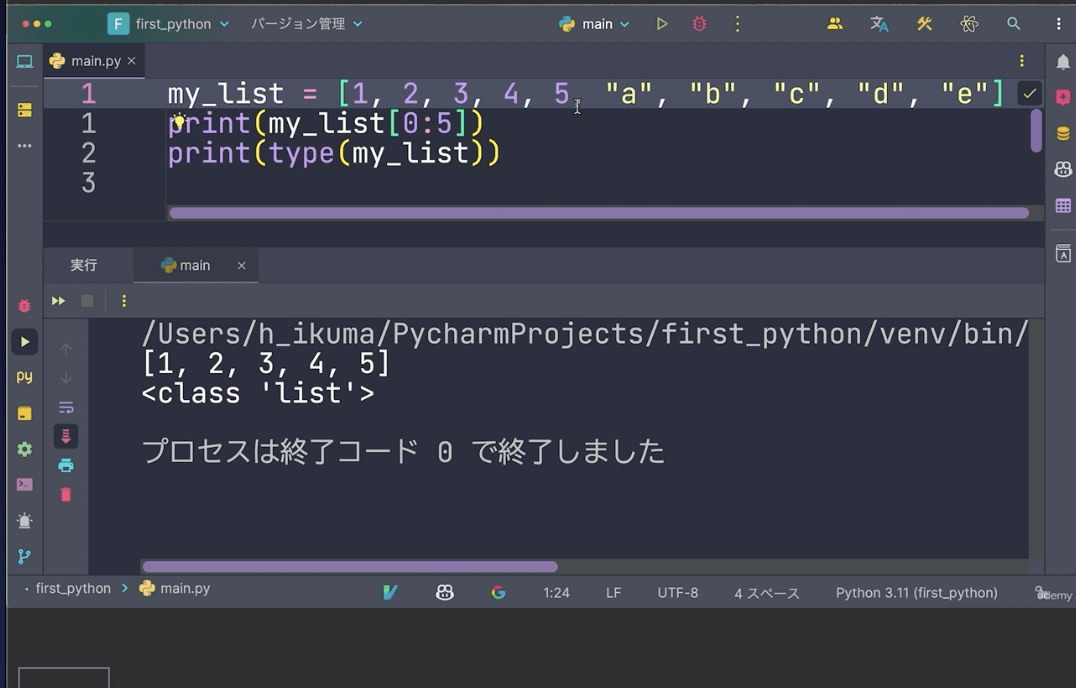
コロンの左側というのは0から始まるインデックスですね。これは先ほどのインデックスと同じです。しかしコロンの右側、今回の場合、5までを取り出したい場合、先頭を0ではなく、1と数えます。
例えば、my_listの1から5までを取り出したいと言う場合は、このコロンの左側というのは先頭のインデックス、そして右側の後は先頭を1と数えて、そこから1、2、3、4、5というふうに、5個取り出しますよと言う意味になります。
ではこのaからeまで、このスライスを使用して取り出してみましょう。どうすればいいかわかりますか? ちょっと考えてみましょう。
aというのは、0から数えて5番目になります。そしてeは1から数えて10番目になります。
print(my_list[5:10])
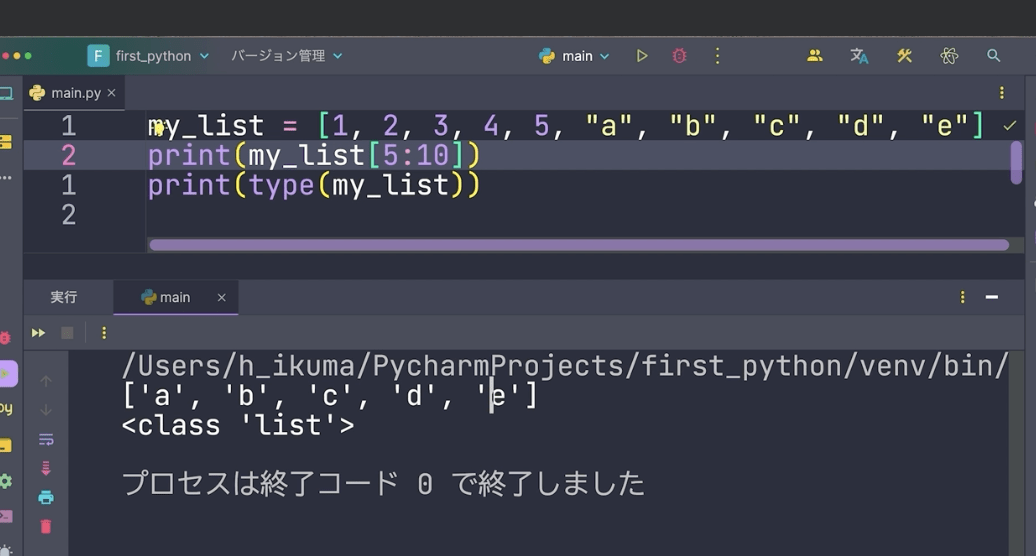
このようにすると、a〜eまで取り出すことができます。
このようにコロンを使うと任意の範囲を取り出すことができます。このコロンの右側が先頭が0ではなく1として始まると言うところが少しややこしいので注意しましょう。
なお、この0は省略することもできます。省略した場合は0と書いた場合と一緒です。
print(my_list[:10])
そしてコロンの右側も省略することが可能です。
print(my_list[:])
実行するとこのリストの先頭から最後までという意味になります。
例えば”a”から右側のすべて取り出したいという場合は
print(my_list[5:])
と書きます。
次はn個飛ばしで取り出したい場合の書き方です。
もしリストから1つ飛ばしで値を取り出したい場合は、コロンをもうひとつ付け加えます。
print(my_list[5::2])
このようにすると、a,c,e が取り出せます。
以下のように入力すると、先頭から末尾までひとつ飛ばして表示されます。
print(my_list[::2])

::の後の値を3にすると今度は2つ飛ばして値を取り出すことができます。

リストから任意の範囲を取り出す場合、このようにコロンで区切って取り出します。実はこのインデックスやスライスはリストに使えるだけではなくて文字列でも使えます。
s = "Python" print(s[1])
このように入力すると、s[1]というのは、Pythonの2番目の文字、yが表示されます。
この文字列も実はリストみたいに複数のデータの塊、ということができます。
Pyothonの文字列は一連のデータ群という言い方もでき、インデックスとかスライスを使って値を取り出すことができます。
ちょっと余談ですが、先日、会社の業務でインボイスの番号を扱うことがありました。その時にインボイス番号、例えばT1-2345-6789-0123のようなものがインボイス番号です。
この文字列からTとかハイフンを取り除いた値を扱いたいと言うことがありました。Tやハイフンを取り除くとインボイス番号ではなくて法人番号になります。この値を取り出す作業を、このインデックスとスライスを使ってやりました。
s = "T1-2345-6789-0123"
print(s[1:].replace("-", ""))これはどういうことか?
まず以下のようにすると先頭の文字であるTを取り除くことができます。
s = "T1-2456-7890-0123" print(s[1:])
コロンの後を省略した場合最後までと言う意味になりますね。
そして1と書いたらこのTが0番目ですから2つ目の「1」が取り出されます。この1というインデックスから末尾までを取り出すとという書き方になります。
さらにハイフンを取り除くためにはリプレイス、置き換えという意味ですが、replaceメソッドを使います。
print(s[1:].replace("-", ""))このように replace メソッドを追加します。コードの意味は、ハイフンを空文字に置換するというものです。
これで実行すると、このようにTとハイフンを取り除いた文字列を取り出すことができます。
s = "T1-2345-6789-0123"
print(s[1:].replace("-", ""))こんなふうにして、インボイスの番号から法人番号にデータを変換しました。
こういう業務が実務ではあります。
仕事内容としては、取引先から送られてきたインボイス番号が、これが正しいものかどうかというのをちゃんとチェックするという意味もありました。
取引先がいっぱいありますよね。それをひとつひとつインボイス検索で国税庁のホームページに飛んでいって、この登録番号のところに一個一個打ち込んでいって確認するなんていう手間のかかることは絶対にやりたくなかったんですね。
せっかくPythonが書けるわけですから、プログラミングを使ってこれを一気に確認したかったということです。そのときに国税庁のホームページに打ち込むのはTとハイフンを除いた数字ということがわかりました。インボイス番号からTとハイフンを除くと法人番号になります。この値を得るためにこんな風にプログラミングしました。
具体的にどうやってこの法人番号からそれがちゃんと正しいものかどうかというのを確認するかというと国税庁が公開しているAPIというものを使って通信して確認すると言うことをやりました。それについてはまた別のコースで扱いたいと思います。
ちょっと脱線が過ぎましたので話を戻しますと、リストから値を取り出すためには。インデックスを使います。インデックスは左から数えて何番目というものです。これは0から始まります。-1にすると後から数えて何番目という取り出し方です。
そしてコロンを使うと任意の範囲を取り出せます。これはスライスという言い方をするんですが、コロンを使って任意の範囲を取り出すことができます。コロンの左側が0から始まるインデックスで、コロンの前に0を省略しても暗黙的に0が使われます。
そしてコロンの右側、これはこの先頭を1と数えて何番目まで取り出すかという指定になります。そして、コロンの右側を省略すると末尾という意味になります。
リストの末尾にデータを追加する方法とデータの書き換え方法
続いてリストに追加する、append というものを見ていきましょう。
例えば1から9までの値が入ったリストがある場合、この9の後にデータを追加していくというメソッドです。実際にやってみましょう。
my_list = [1, 2, 3, 4, 5, "a", "b", "c", "d", "e"]
my_list.append("f")
print(my_list)my_list には最初、1から5、aからeが格納されています。このリストに append で f を追加してみます。すると最初は e までしかなかったリストの結果に f が追加されます。
では my_list に10を追加してみます。
my_list.append(10) print(my_list)
この状態でprint関数で出力すると、fの後に10と追加されます。こんなふうにappendしていくと、どんどんリストの末尾に追加することができます。
appendという話をしたついでに、リストの中身の書き換えもやってみたいと思います。
例えばmy_listの先頭のこの1。この数字の1を書き換えてみたいと思います。
my_list[0] = "1" print(my_list)
この場合、インデックスを指定します。リストの最初は[0]ですね。
数値の1を書き換え、文字列の”1″にしてみます。

そうすると、最初は数値の1だったものが、文字列の”1″に変わります。このように書き換えはインデックスを指定して行います。
ということで、リストに追加 = append する方法でした。
リストを並び替える方法を理解する
では次はリストの並び替えも見ていきます。
リストの並び替えには2つ種類があります。
sort メソッド
my_list.sort() を実行しますと、小さい順に並び変わります。
なお、小さい順に並び替える事を昇順、大きい順に並び替えることを降順といいます。
降順にするか、昇順にするかは任意に変えることができます(後述)。
上記画像1つ目の sort メソッドというのは、元のリストが指定した順番に書き変わってしまいます。
2つ目の sorted メソッドというものは、元のリストは書き変わらずに並び替えた事象が返ってきます。(後述)
まずはsortメソッドからです。
my_list = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1] my_list.sort() print(my_list)
このコードは小さい順に並び変わります。この時一つ注意がありまして、リストの中身は、同じ型でないとエラーになります。
このmy_listには全てint型が入っているんですが、文字列の”1″がはいっているとエラーになります。
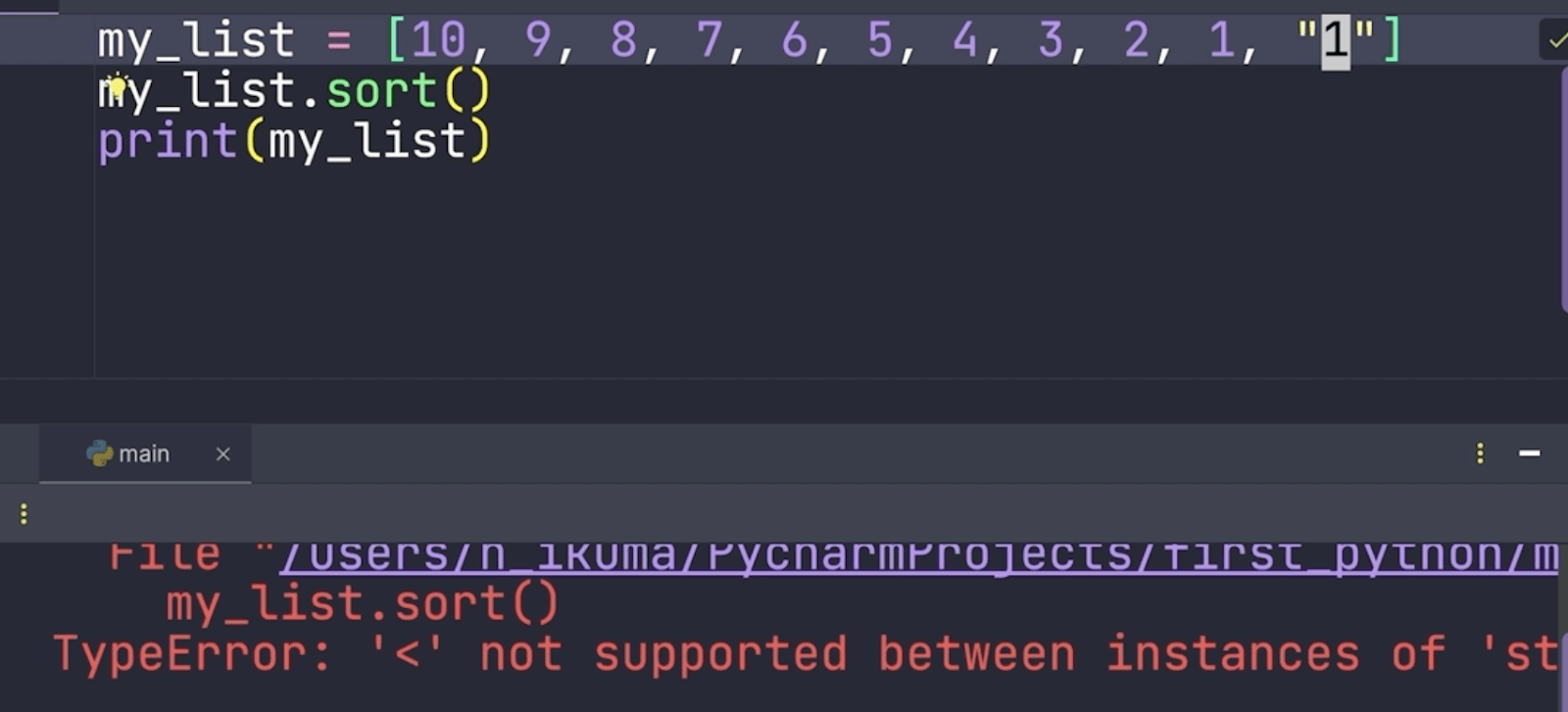
タイプエラーですね。型にまつわるエラーです。このように、並べ替えするときは別の型を混ぜてはいけません。
先ほどは数値の並び替えでしたが、次は文字列の並べ替えをしてみます。例えばB,C,Aみたいなアルファベットでリストを作成した場合はABC順になります。
my_list = ["b", "c", "a"] my_list.sort() print(my_list)
上記コードの結果は、

となります。
そして、今、小さい順でやっていますが大きい順、降順に並べ替えてみましょう。
降順にするにはsortメソッド()の中にreverse=Trueと記述します。
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9] my_list.sort(reverse=True) print(my_list)
実行結果は数字が大きいもの順、降順に変わります。アルファベットでも同様です。
ぜひご自身でも試してみてください。
ちなみにこのメソッドとか関数の中に入れる括弧の中に書く値を引数と言います。関数やメソッドに与えるオプションです。reverse という引数名に対してTrueという値を与えています。(引数については関数のチャプターで詳しく解説します)
この引数を与えることによって、このsortメソッドの挙動を変えられます。
さらに余談ですが、10.0などのfloat型をリストにまぜるとどうなるでしょうか?
これは実はうまくいきます。
int型とfloat型は異なる型ですが、この2つはちょっと特別な関係にあり、違う型でも混ぜても大丈夫です。
sorted関数
次はsorted関数というものを見てみます。
ここまでやってきたsortメソッドは、元のリストを書き換えるというものでした。my_list.sort()というように、ドットの後に続くものは概ねメソッドと言うことができます。
一方、sorted関数は元のリストは書き換わらずに並び替えたリストが返ってくるものです。関数ですから独立して使うことができます。
sorted関数は引数としてリストを渡すと中で処理が行われて、処理結果を左辺に返します。

以下のコードは並び替えたリストをまず表示して、その後に元のリストを表示しています。
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10.0] sorted_list = sorted(my_list, reverse=True) print(sorted_list) print(my_list)
実行すると、まず並び替えたリストは10.0から降順に結果を返しています。しかし、その下の my_list の結果は変わっていません。
このように、sortedメソッドとsort関数では挙動に違いがあります。なお、sortメソッドのように元のデータが書き変えてしまうメソッドを破壊的メソッドと言います。副作用がある、といったりもします。
通常は副作用がないsorted関数を用いて別の変数に代入するのが望ましいです。
このような概念があると覚えておくとプログラミングへの理解が深まるかと思いますので、頭の片隅に入れておきましょう。
任意のデータがリストに含まれているかどうか判定する 「in 演算子」
続いてin演算子で要素の有無を調べる内容を見ていきます。別のところで軽く触れましたが、復習の意味で再度説明いたします。
in演算子はstr型だけではなく、いろいろなデータの塊に対して要素の有無を調べることができます。
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10.0] result = 10 in my_list print(result)
my_list の中に10は入っていますか? と聞いています。実行結果はTrueとなります。
10.0はfloat型ですが、in演算子を使用してint型で尋ねても、int型とfloat型は型が違ってもうまくいきます。in演算子の結果はTrueかFalseです。
判定結果の真偽値が返ってくるということになります。
では文字列の中でin演算子を使用したらどうなるでしょうか?
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] result = "10" in my_list print(result)
結果はFalseになります。違う型だから同じとはみなされません。
では、応用問題としてこの結果をTrueにするにはどうすればいいでしょうか?
ちょっと考えてみましょう。
答えはint関数でキャストします。int関数を覚えていますでしょうか?
随分前に文字列からint関数とかfloat関数で型変換つまりキャストできますと話をしました。
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, "10"]
result = int("10") in my_list
print(result)int関数を使うと、文字列の中が数値の10、int型の10になりますのでTrueになります。文字列をキャストして比較することがあります。こういうテクニックを覚えておきましょう。
ネスト(入れ子) されたリストの作り方と取り出し方

リスト型最後のトピックとしてネストされたリストについて学んでいきましょう。どういうものかというと、入れ子になったリストです。「リストの中のリスト」を「ネストされたリスト」なんていいます。
以下のコードでは角括弧の中にさらにリストがあります。これがネストされたリストです。
my_list = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] print(my_list[0]) # [1, 2, 3] print(my_list[0][1]) # 2
そして、値を取り出すとき、[0]といった場合は、リストの中の0番目の要素である、[1, 2, 3] というリストが取り出されます。
print(my_list[0]) #[1, 2, 3]
この[1, 2, 3]というリストに対して[1]と書いて2という数値を取り出すことができます。
print(my_list[0][1]) #2
ネストは以下のコメントアウトしたように改行して記述するのではなく、一行にまとめることもできます。
# my_list = [ # [1, 2, 3], # [4, 5, 6], # [7, 8, 9] # ] my_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
このように、見やすいように書けるところがPythonの柔軟なところです。では、リストの中の値を取り出してみたいと思います。
my_list = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] value = my_list[0] value2 = value[1] print(value2) # 2
変数valueの値は、[1, 2, 3]になります。そのvalueの2番目の要素が、print関数で表示されています。
このように2段階に分けて記述していますが、次のようにつなげて書くこともできます。
value = my_list[0][1]
例えば1から末尾までみたいに、次のように書くこともできます。
value = my_list[0][1:]
すると結果は、[2, 3]となります。
ちなみに、この nested_list に対して append した場合どうなるでしょうか?
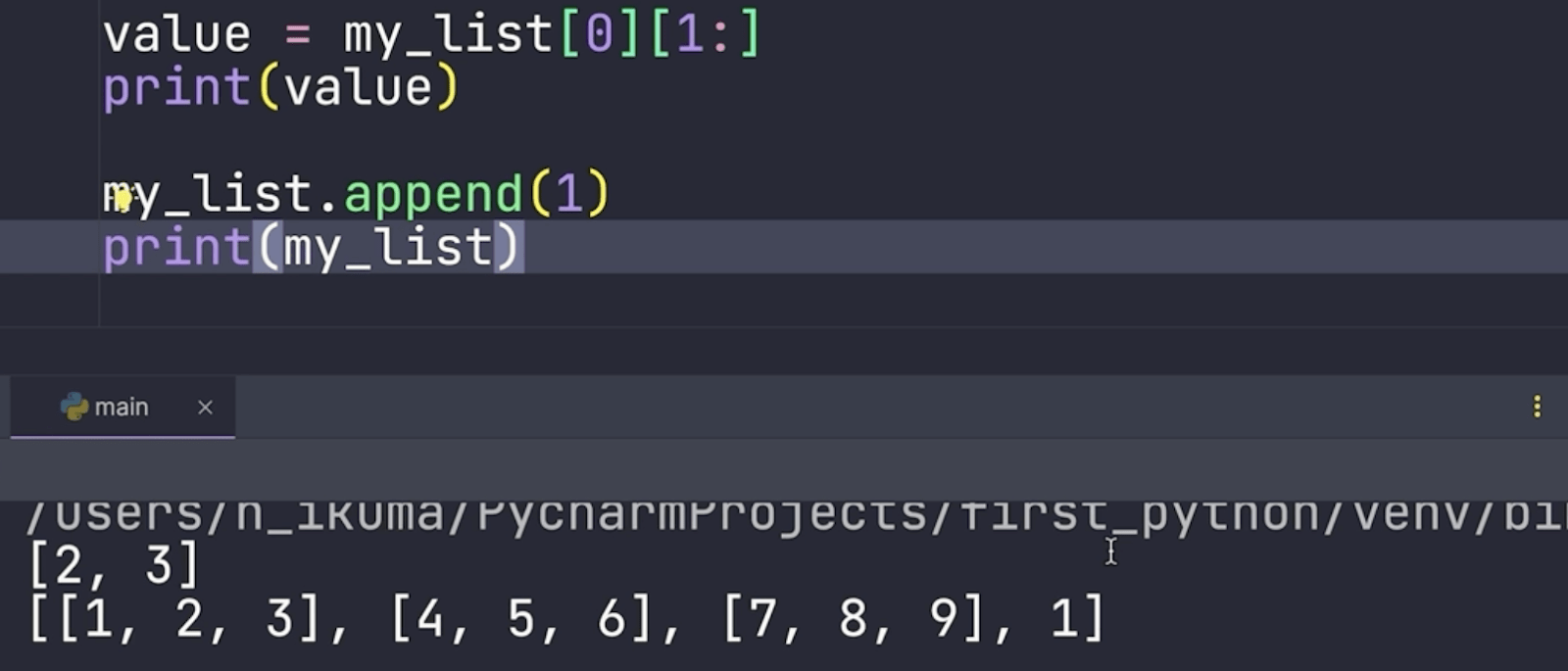
ネストされたリストの末尾に単体の1が加わります。
append メソッドは単体の値だけではなく、リストも追加できます。。
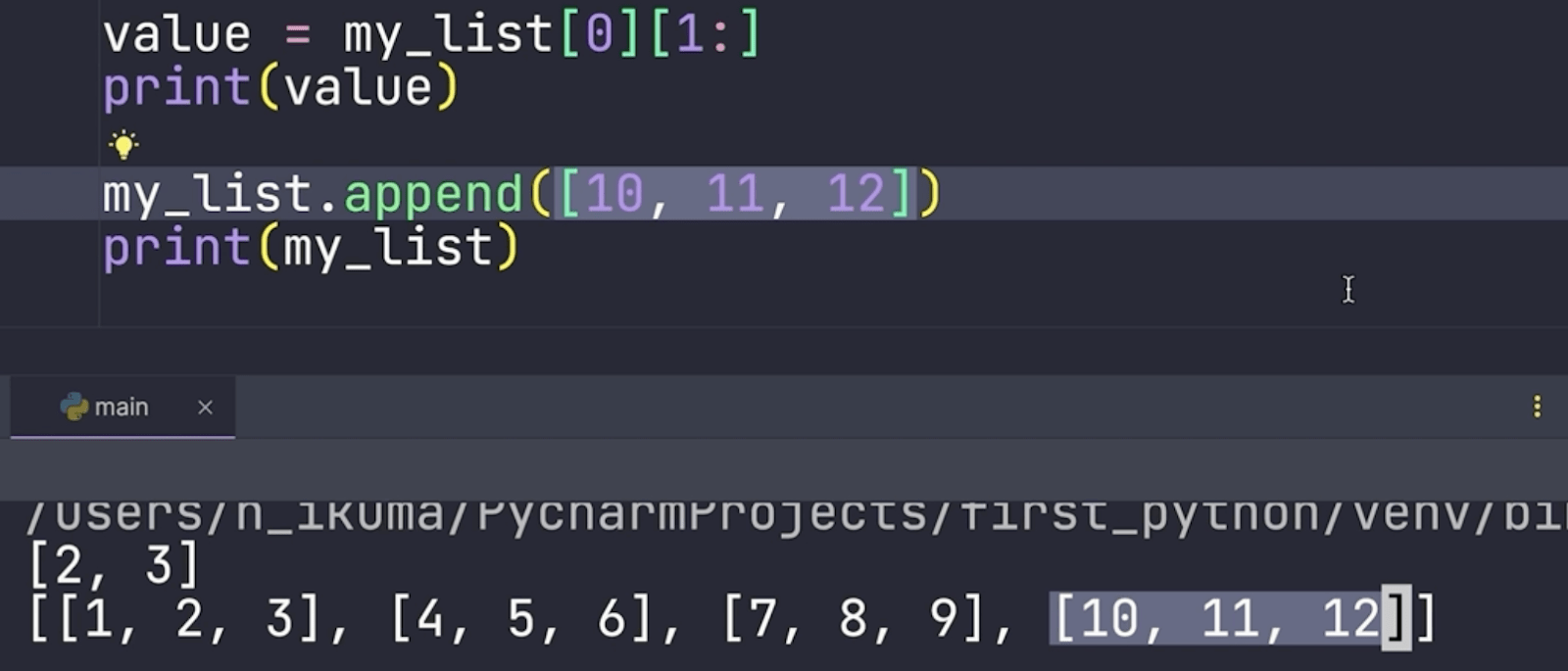
ネストの中にネストを作ることもできます。二重に角括弧がある部分がネストされたリストの中のリストです。
my_list = [ [1, 2, 3], [4, 5, 6], [ [7, 8, 9], [10, 11, 12] ] ] print(my_list) # [[1, 2, 3], [4, 5, 6], [[7, 8, 9], [10, 11, 12]]]
ややこしいですね。
この中から値を取り出したい場合、例えば数字の9を取り出したい場合は、
print(my_list[2][0][-1])
最初のリストの3番目になりますので、[2]となります。次がネストされたリストの中の1番目ですから、[0]となります。その中の最後ですから、[-1]と指定して、末尾の要素を取り出せます。
一応このようにネストの中のネストも解説はしましたが、本シリーズではここまで複雑なことはやりません。
このリストの中には、何でも入れられます。つまり異なる型でも入れられます。それはネストされたリストであっても同じです。
この数字の9が文字列の”9″であっても取り出すことができます。

異なる型でもネストに入れることができます。
なぜこういう話をしたかというと、本シリーズで作るアプリはこのリストの中に、辞書というものをいれるからです。(辞書は後述します)
具体的にはChatGPTにリクエストする時、リストの中に辞書をいれてAIに投げます。
これはネストされたリストではなくて、リストの中の辞書という感じですが、考え方はここまで扱ってきたものと同じです。
この書き方については後で詳しく触れていきます。