 パイソンエンジニア部
パイソンエンジニア部
AIエージェントを構築するとき、誰もが同じ壁にぶつかります。
「賢いモデルを使えば精度は上がる。でも、コストが跳ね上がる。」
Opusをフルで動かすと1タスクあたりの費用がかさむ。だからといってHaikuやSonnetだけで回すと、複雑な判断の場面で詰まる。ずっとどちらかを選ぶしかないと思っていませんでしたか?
Anthropicが2026年3月にリリースしたAdvisor Toolは、この二択を崩します。
安いモデルが実行を担い、判断が難しい局面でだけOpusに相談する。BrowseCompというベンチマークでは、Haikuのスコアが19.7%から41.2%へ2倍以上に跳ね上がりました。しかもコストはSonnet単体より安い。
この発想はどこから来たのか
Advisor Toolの背景には、UC Berkeleyの研究チームが2025年10月に発表した論文があります。タイトルは “How to Train Your Advisor: Steering Black-Box LLMs with ADVISOR MODELS”。
この論文が指摘した問題はシンプルです。
GPT-5やClaudeのような最先端モデルは、APIとして使う限り「ブラックボックス」です。重みを書き換えたりファインチューニングしたりはできない。カスタマイズの手段はプロンプトだけ。ところが、固定されたプロンプトには構造的な限界があります——入力が変わっても対応を変えられないし、コンテキスト長にも上限がある。
UC Berkeleyの研究者が提案した解決策は次のものです。
小さなオープンウェイトモデルを訓練して、大きなブラックボックスモデルに向けて「動的なアドバイス」を生成させる。
アドバイスは自然言語です。タスクの内容に応じて毎回カスタムの指示を生成し、モデルの出力を誘導します。
- GPT-5のRuleArena(税務申告ベンチマーク)スコアが71%改善
- Gemini 3 ProのSWEエージェントタスクのステップ数が24.6%削減
- 静的プロンプトオプティマイザ(40〜60%)に対して85〜100%で上回る
GPT-4o miniのような安価なモデルで訓練したAdvisorが、GPT-5のような最先端モデルにも改善効果を転移できました。GPTで訓練したAdvisorがClaudeにも効いた、という結果も出ています。
アドバイスが自然言語だから、特定のモデルに縛られずに汎化する、これが理由です。この研究が実証したことを、AnthropicがAPIとして実装したのがClaude Advisor Toolです。
Advisorは「考える役」、Executorは「動く役」
Advisor Toolの設計は、一般的なマルチモデル構成とは発想が逆です。
よくある設計では、大きなモデルがオーケストレーターとして全体を指示し、小さなモデルが作業をこなします。大きいモデルが「頭脳」で、小さいモデルが「手足」。
Advisor Toolは逆です。

SonnetかHaikuがExecutor(実行者)として、タスクをエンドツーエンドで担います。ツールを呼び、結果を読み、次のアクションを決める。すべてExecutorの仕事です。
Executorが自分では判断できない局面に来たとき、初めてAdvisor(Opusなど)に相談します。
OpusはExecutorの持つすべての情報を確認します。システムプロンプト、ツール定義、それまでの会話履歴、ツール結果——全部です。そのうえで、次の3つのうちいずれかを返します。
- このあとの進め方のプラン
- 現在のアプローチへの修正指示
- タスク完了のストップシグナル
Advisorは、ユーザーに見えるアウトプットを一切出しません。ツールも呼びません。ただExecutorにアドバイスを返して、Executorに戻す。それだけです。だから安い。
Opusが生成するのは、1回のアドバイスにつき400〜700トークンの短い指示文です。膨大なアウトプットを生成するのはSonnetかHaikuの仕事。Opusには「判断だけ」してもらう。Opusに全部任せるより格段に安く、Haiku単体より格段に賢い、このトレードオフが実現します。
なぜアドバイスがモデルをまたいで転移するのか
GPT-4o miniで訓練したAdvisorがGPT-5にも効き、GPTで訓練したAdvisorがClaudeにも効きます。アドバイスが自然言語だからです。特定のモデルアーキテクチャに依存しない。「どう進めるべきか」という自然言語の指示は、どのモデルでも理解できます。
研究者はこれを「learning to adviseはプロンプトエンジニアリングを静的な探索問題から、インスタンスごとにカスタムアドバイスを生成する学習済みポリシーへ変える」と表現しています。
実際の数字で見る
コーディングタスク(SWE-bench Multilingual)
9言語にまたがるコーディング能力テストです。
| 構成 | 精度 | タスク単価 |
|---|---|---|
| Sonnet 4.6 単体 | 72.1% | $1.09 |
| Sonnet 4.6 + Opus Advisor | 74.8% | $0.96 |
精度が2.7ポイント上がり、コストは11.9%下がりました。
エージェント検索(BrowseComp)
| 構成 | 精度 | タスク単価 |
|---|---|---|
| Sonnet 単体 | 58.1% | $7.00 |
| Sonnet + Opus Advisor | 60.4% | $6.13 |
| Haiku 単体 | 19.7% | — |
| Haiku + Opus Advisor | 41.2% | — |
私が一番驚いたのはHaikuの数字です。19.7%から41.2%——2倍以上です。
ターミナルコーディング(Terminal-Bench 2.0)
| 構成 | 精度 | タスク単価 |
|---|---|---|
| Sonnet 単体 | 59.6% | $0.94 |
| Sonnet + Opus Advisor | 63.4% | $0.88 |
| Haiku 単体 | 35.7% | — |
| Haiku + Opus Advisor | 49.0% | — |
Haiku + Opus AdvisorはSonnet単体より29%スコアが低いです。でも、コストは85%安い。精度がある程度あれば十分な大量処理タスクでは、十分な選択肢です。
実装する
Advisor ToolはClaude APIのベータ機能として利用可能です(2026年3月時点)。実装は tools 配列にAdvisorを追加するだけです。
最小構成のPythonコード
import anthropic
client = anthropic.Anthropic()
response = client.beta.messages.create( model="claude-sonnet-4-6", # Executor max_tokens=4096, betas=["advisor-tool-2026-03-01"], tools=[ { "type": "advisor_20260301", "name": "advisor", "model": "claude-opus-4-6", # Advisor } ], messages=[ { "role": "user", "content": "Goでグレースフルシャットダウン付きの並行ワーカープールを作ってください。", } ],
)betas=["advisor-tool-2026-03-01"] は必須です。このヘッダーがないとエラーになります。
Executorは model= の最上位で指定し、Advisorは tools 配列の中で指定する——この構造を押さえておけば迷いません。
1リクエストの中で何が起きているか
ExecutorがAdvisorを呼ぶと、1回の /v1/messages リクエストの中で次のことが起きます。
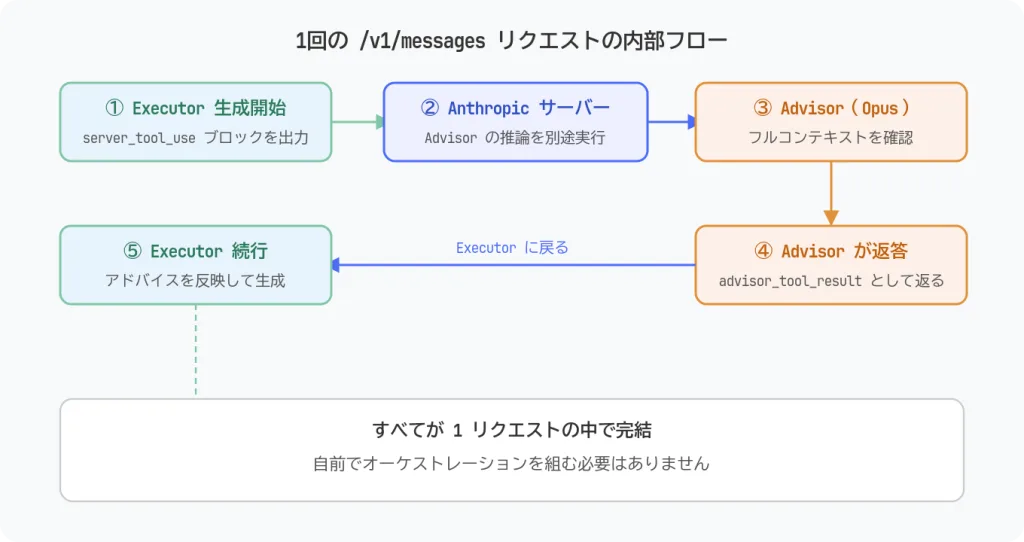
オーケストレーションを自分で組む必要はありません。Advisorをいつ呼ぶかは、Executorが自律的に判断します。
モデルの組み合わせルール
AdvisorはExecutorより高性能なモデルを指定する必要があります。有効な組み合わせは次の通りです。
| Executor | 指定できる Advisor |
|---|---|
| Haiku | Sonnet、Opus |
| Sonnet | Opus |
逆(OpusをExecutorにしてHaikuをAdvisorにするなど)を指定すると、APIが 400 invalid_request_error を返します。
コスト管理:max_uses で呼び出し回数を制限する
max_uses でAdvisorの呼び出し回数を上限設定できます。
tools=[ { "type": "advisor_20260301", "name": "advisor", "model": "claude-opus-4-6", "max_uses": 3, # 1リクエストあたり最大3回 }
]上限に達するとExecutorはAdvisorなしで処理を続けます。コストを見積もりやすくするため、最初は小さい値から試すのが無難です。
料金の仕組みはシンプルです。AdvisorのトークンはOpusの料金、ExecutorのトークンはSonnet/Haikuの料金で別々に課金されます。
使用量の内訳は usage.iterations[] で確認できます。
{ "usage": { "input_tokens": 412, "output_tokens": 531, "iterations": [ { "type": "message", "input_tokens": 412, "output_tokens": 89 }, { "type": "advisor_message", "model": "claude-opus-4-6", "input_tokens": 823, "output_tokens": 1612 }, { "type": "message", "input_tokens": 1348, "output_tokens": 442 } ] }
}type: "advisor_message" がOpusの料金、type: "message" がExecutorの料金です。どのイテレーションでどれだけOpusを使ったかが一目でわかります。
他のツールとの組み合わせ
Advisor Toolは既存のツールと共存できます。同じ tools 配列に並べるだけです。
tools = [ { "type": "web_search_20250305", "name": "web_search", "max_uses": 5, }, { "type": "advisor_20260301", "name": "advisor", "model": "claude-opus-4-6", }, { "name": "run_bash", "description": "Bashコマンドを実行する", "input_schema": { "type": "object", "properties": {"command": {"type": "string"}}, }, },
]WebSearchを呼び、Advisorに相談し、Bashコマンドを実行する——これが同じターンの中で起きます。Advisorのプランが次にどのツールを使うかを方向付けることもできます。
私がAdvisor Toolを試したとき、正直「もっと複雑な設定が必要では」と思っていました。実際には tools 配列に4行足すだけでした。構造がシンプルなぶん、モデルの組み合わせとmax_usesの設定を最初にちゃんと決めておくのがポイントで、そこだけ手を抜くとコストが予想外に膨らみます。
TL;DR
- Advisor Tool はExecutor(安いモデル)が複雑な判断の局面だけOpusに相談しながら動く仕組み
- AdvisorはOpusが400〜700トークンの短い指示を返すのみ。ユーザー向けアウトプットは出さない
- Haiku + Opus AdvisorはBrowseCompで19.7%→41.2%、スコアが2倍以上に
- Sonnet + Opus AdvisorはコーディングタスクでSonnet単体より精度UP・コストDOWN(+2.7pt、-11.9%)を同時に実現
- 実装は
betas=["advisor-tool-2026-03-01"]とtools配列へのAdvisor追加だけ max_usesでAdvisor呼び出し回数を制限してコストをコントロールできる- AdvisorはExecutorより高性能なモデルを指定すること(逆は400エラー)
- Advisor TokenはOpus料金、Executor TokenはSonnet/Haiku料金で別々に課金される
